

Is Mdp A Type Of Q-learning
Why does Markov Decision Process thing in Reinforcement Learning?
Comparison between MDP and k-armed brigand problems to see how MDP is amend-fitted in the real earth
For near learners, the Markov Conclusion Process(MDP) framework is the first to know when diving into Reinforcement Learning (RL). Notwithstanding, can you explain why information technology is so important? Why not another framework? In this mail, I will explain the advantages of MDP compared to the k-armed bandit trouble, another popular RL framework.
The mail service is inspired by an RL specialization offered past University of Alberta and Alberta Machine Intelligence Institute on Coursera. I wrote this post to summarize some of the videos and get a deeper understanding of the specialization.
The objective of Reinforcement Learning
Before diving into our leading trouble, I want to mention the primary goal of RL, every bit it matters when we choose a framework to build a model. In RL problems, we desire to maximize the total rewards nosotros receive past taking activity over time. We are not told what actions lead to higher rewards. Instead, we acquire it from experience. We repeat endeavor-and-fault attempts and observe which activeness gives us a higher advantage and which gives a lower reward. Moreover, nosotros are not even told when rewards are given in the get-go. They might exist given immediately or might be given after a few time steps after we accept activity. Therefore, we need a dynamical framework that captures those 2 features, "effort-and-error search" and "delayed rewards."
Instance: Rabbit exploring foods
Nosotros think near a simple situation. There is a hungry rabbit looking for foods to fill her appetite immediately. There is a carrot on its right and broccoli on its left. The rabbit prefers carrots to broccoli, then she receives a +x reward when she eats a carrot. On the other hand, broccoli generates a reward of but +3. In each time, the rabbit will choose a carrot because she knows choosing a carrot is an optimal action(= action that leads to the possible highest reward).

What if the positions of a carrot and a broccoli switch? The rabbit will likewise cull a carrot again because the positions of foods practice non affect the rewards the rabbit will receive. This is actually an example of a simple "k-armed bandit" problem.

K-armed Bandits
The 1000-armed brigand problem is 1 of the about simplest but powerful frameworks in RL. It is named past analogy to "one-armed bandit"(= a slot automobile) although the framework has thou levers instead of i. In the problem, you confront a pick amongst m unlike options. After each pick, you receive a advantage chosen from a stationary probability distribution respective to the option you chose. You lot repeat such selections and aim to maximize the total corporeality of rewards y'all receive. To do so, you need to find a lever (or option) that is most likely to generate the best reward and to concentrate your selections on it.
The rabbit example can be treated every bit a "two-armed bandit" trouble because the rabbit ever has two options to choose from, the carrot and broccoli. Choosing the carrot generates +10 with 100% probability and choosing the broccoli generates +3 with 100 probability respectively. Because the rabbit wants to maximize the full amount of rewards, information technology always chooses carrots.
The following commodity will be helpful to understand the k-armed bandit problem more in particular.
Example Cont'd: Tiger behind the carrot
While the k-armed bandit framework captures the previous simple situations very well, it has a limit, which is shown in the adjacent state of affairs.
Here, we think about a tiger that is behind the carrot and hunting rabbits. When the rabbit eats the carrot, there are no longer any obstacles between the rabbit and tiger. The tiger runs faster than the rabbit does, so she cannot run away. The rabbit ends up being chase and receives a -100 reward.
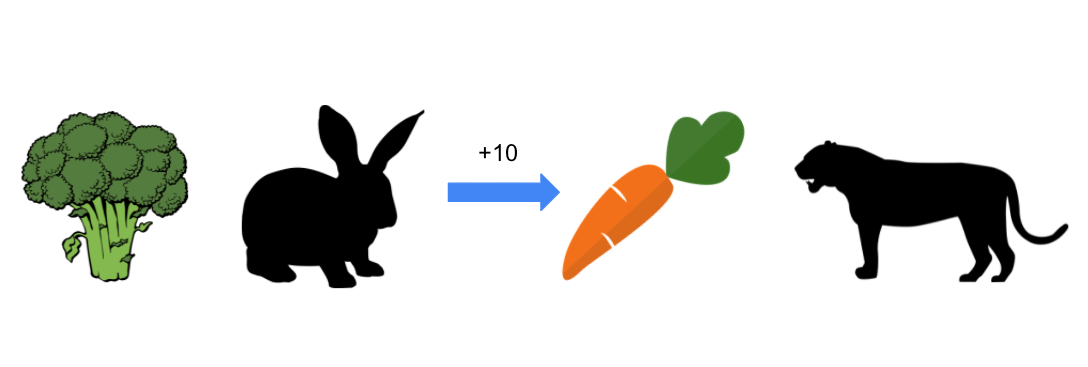
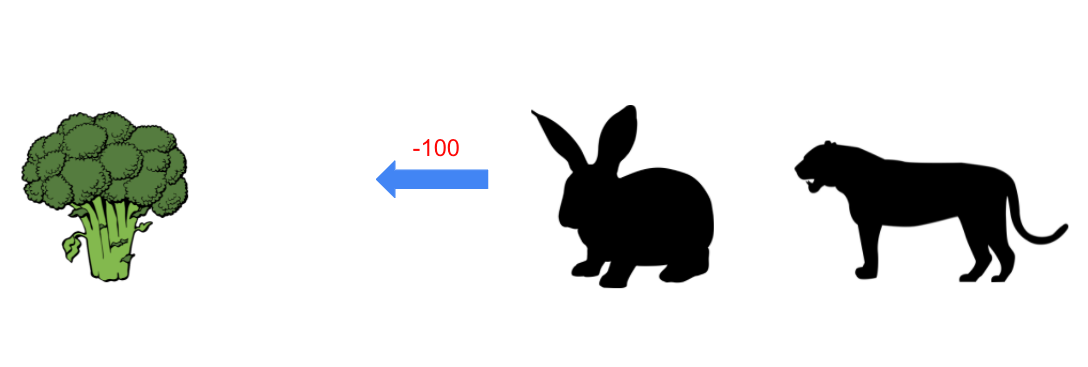
If the rabbit chooses to eat the broccoli, the rabbit receives +3 and remains safe.

In the m-armed bandit problem, the rabbit keeps choosing a carrot even if she knows there is a tiger behind it considering changing situations practice not impact its optimal activity. However, keeping choosing a carrot will not assist the rabbit forever. How should we consider a change in the situation into our problem definition?
Markov Decision Procedure
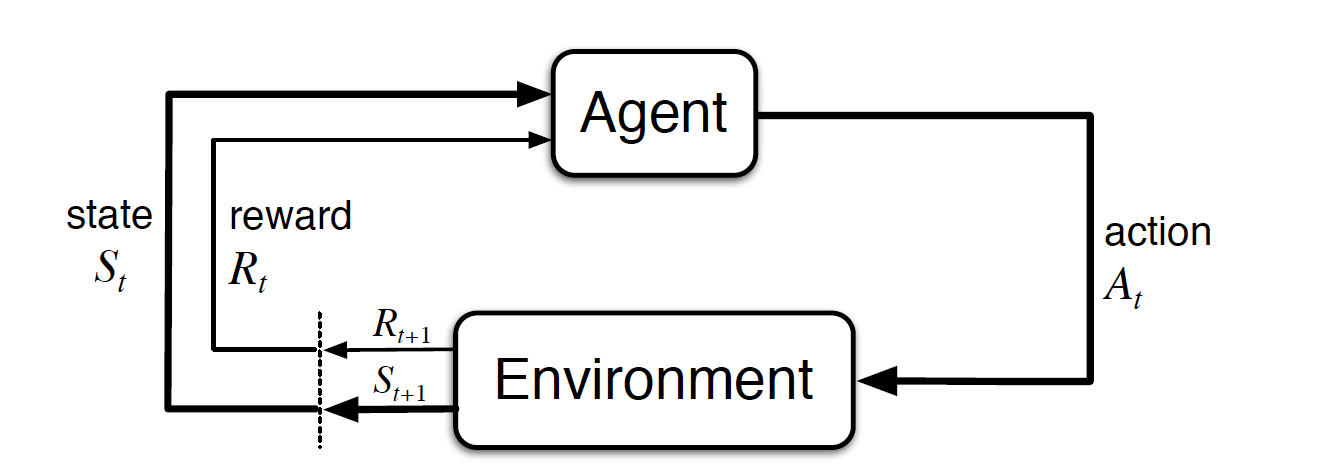
Finally, we introduce Markov Decision Process(MDP) to solve such a trouble. An MDP consists of 2 elements; the agent and the environment. The agent is a learner or decision-maker. In the above example, the amanuensis is the rabbit. The surroundings is everything surrounding the agent. In the case, the environment includes everything in the field where the rabbit is with food and the tiger. Later the agent taking an action, we face a different state of affairs. We call these different situations states. For example, the situation where the rabbit has not moved yet is considered as a state, and the situation where the rabbit is between the broccoli and the tiger after she eats the carrot is considered as another land.
In the MDP, the agent "interacts" with the environs. The agent chooses an action and observes what happens in the surroundings later it took the activeness. Then, it receives a reward in correspondence with the action and the country she transitioned to. The agent repeats the interaction many times and learns what action is optimal at each country.
The following diagram is a formalization of MDP. At time t, the agent at state St chooses an action At from the activeness infinite and the environment returns a new state S_t+1 from the land infinite. And then, the agent receives the reward R_t+1 depending on the starting state, the taken action, and the subsequent state.
In the rabbit example, the action space consists of moving right and left. The state space includes all the four possible situations, 1) the rabbit is at the initial position, two) the rabbit is between the broccoli and tiger, 3)the rabbit is the leftmost after eating the broccoli, and 4)The rabbit being eaten by the tiger. The possible rewards are +3(Situation 2), +ten(Situation 3), and -100(Situation 4). The details are described in the following diagram.
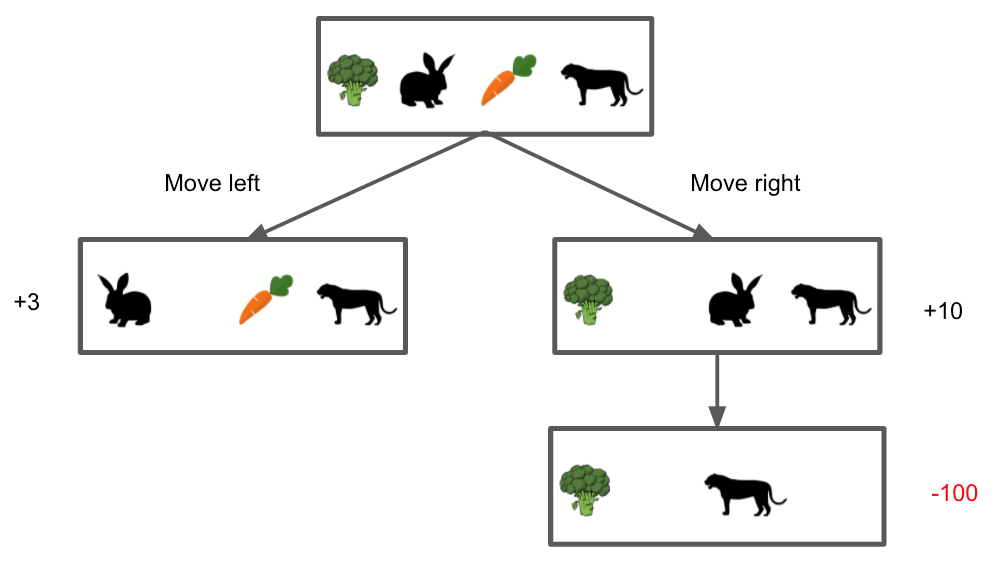
Considering the MDP framework and the diagram, the rabbit knows the optimal action is moving right(=going for the broccoli) considering eating the carrot generates negative total rewards in the stop.
Technically, MDP captures the dynamism of RL problems by defining the dynamics function of the MDP, which is a probability distribution of pairs of a country and a subsequent reward, conditional on its previous state and the taken action there. Nevertheless, I will relieve an explanation about this for another article I volition write in the future.
Summary
- The MDP framework is of import considering it accounts for a change in situations that might atomic number 82 to alter in optimal action, which is not considered in the k-armed bandit framework
- An MDP consists of its agent and environment. The agent interacts with the environment observing transitions of states and receiving rewards to find an optimal activeness at each state
Reference
- [i] R.Sutton and A.Barto, Reinforcement Learning An Introduction, 2nd edition(2018), The MIT Press
- Reinforcement Learning Specialization on Coursera

Is Mdp A Type Of Q-learning,
Source: https://towardsdatascience.com/why-does-malkov-decision-process-matter-in-reinforcement-learning-b111b46b41bd
Posted by: reedythrome.blogspot.com
0 Response to "Is Mdp A Type Of Q-learning"
Post a Comment